TL;DR
Security fatigue is becoming one of the most overlooked challenges in cybersecurity today. A recent report by Sophos found that 85% of cybersecurity and IT professionals in the Asia-Pacific region are already experiencing burnout or fatigue.
Security fatigue is becoming one of the most overlooked challenges in cybersecurity today. A recent report by Sophos found that
85% of cybersecurity and IT professionals in the Asia-Pacific region are already experiencing burnout or fatigue. That means even before a major attack happens, many teams are already running on empty.
Endless alerts, duplicate findings, and tool overload have become a daily struggle. Every ticket demands attention, yet most turn out to be noise. Over time, that constant grind erodes focus and morale, making it harder for teams to respond effectively when it truly counts.
The problem isn’t a lack of skill or effort. It’s a system issue. Security teams are buried under alerts without context, vulnerabilities without prioritization, and too many manual steps that drain time and energy. When fatigue sets in, speed and accuracy both start to slip.
At some point, even the best analysts stop asking how to fix everything and start wondering what’s the point of fixing anything at all. That’s when fatigue turns into risk, and the real cost begins to take effect.
What’s Really Behind Security Fatigue

Security fatigue does not appear overnight. It builds slowly under workloads, metrics, and meetings until the team starts running on autopilot. The causes are rarely personal. They are built into how most security programs operate.
Here’s what usually drives it:
-
Most organizations use too many tools that do not communicate well with each other. SAST, DAST, CSPM, ticketing systems, and vulnerability scanners all have their own dashboards, reports, and alerts. Analysts spend more time reconciling results than actually fixing issues.
-
Lack of context
When every vulnerability looks urgent, nothing feels prioritized. Without understanding which assets are critical or exploitable, teams treat everything as high risk. The result is noise instead of insight.
-
Broken workflows
Tickets reopen, validation is manual, and every fix leads to another test cycle. Reporting turns into a race to meet deadlines instead of a process for improving security posture.
-
Human burnout
Fatigue spreads quietly. Late nights become routine, and constant pressure to keep up turns into disengagement. Some leave the team altogether, and replacing that talent costs far more than anyone expects.
By the time leaders notice, the effects are already visible. Response times slow down, remediation becomes inconsistent, and costs rise in the background.
The real question is not why teams burn out but how much that burnout is costing the organization every single day.
The Hidden Financial Impact of Security Fatigue
Security fatigue is not just a people problem. It is a financial one. Every repetitive task, delayed fix, or missed alert quietly adds up in cost. While few companies measure it directly, the impact is hiding in plain sight across three major areas: wasted time, poor remediation efficiency, and talent loss.
1. Wasted Time on False Positives
Security teams spend a large share of their day investigating alerts that never lead to real threats. According to a 2024 study, analysts waste up to 27% of their time each week chasing false positives. That time could have been used to investigate real risks or improve overall posture. For a 10-member team, that is roughly 100 hours of lost productivity per week, translating into thousands of dollars each month.
Fatigue not only affects morale, but it also slows everything down. When analysts are overworked, the mean time to remediate (MTTR) rises, and small issues stay unresolved for longer. A study found that organizations with staff shortages or burnout experienced breach costs that were 1.76 million dollars higher on average. The financial hit often comes not from one big mistake, but from hundreds of tiny delays caused by exhaustion and overload.
3. Rising Attrition and Replacement Costs
Burnout drives turnover. The global cybersecurity talent shortage already stands at more than 4 million professionals, as reported. Losing a trained analyst means months of hiring and retraining, plus higher salary expectations due to market demand. On average, replacing one experienced security engineer can cost between 30,000 and 50,000 dollars when you include lost productivity and recruitment costs.
4. The Multiplying Effect of Fatigue
These factors do not operate separately. They reinforce one another. More false positives create more work. More work increases fatigue. Fatigue slows remediation. Slower remediation increases breach risk, which leads to more incidents and, again, more work. The loop keeps turning until teams are stuck in a cycle of stress, backlog, and financial loss.
The hardest part is that many organizations never see this cost line in their budget. It is buried in overtime hours, contract extensions, and missed service-level targets. Yet the total impact is real. For large enterprises, security fatigue can quietly drain hundreds of thousands of dollars every year in operational waste and lost focus.
How to Break the Cycle of Fatigue and Regain Focus
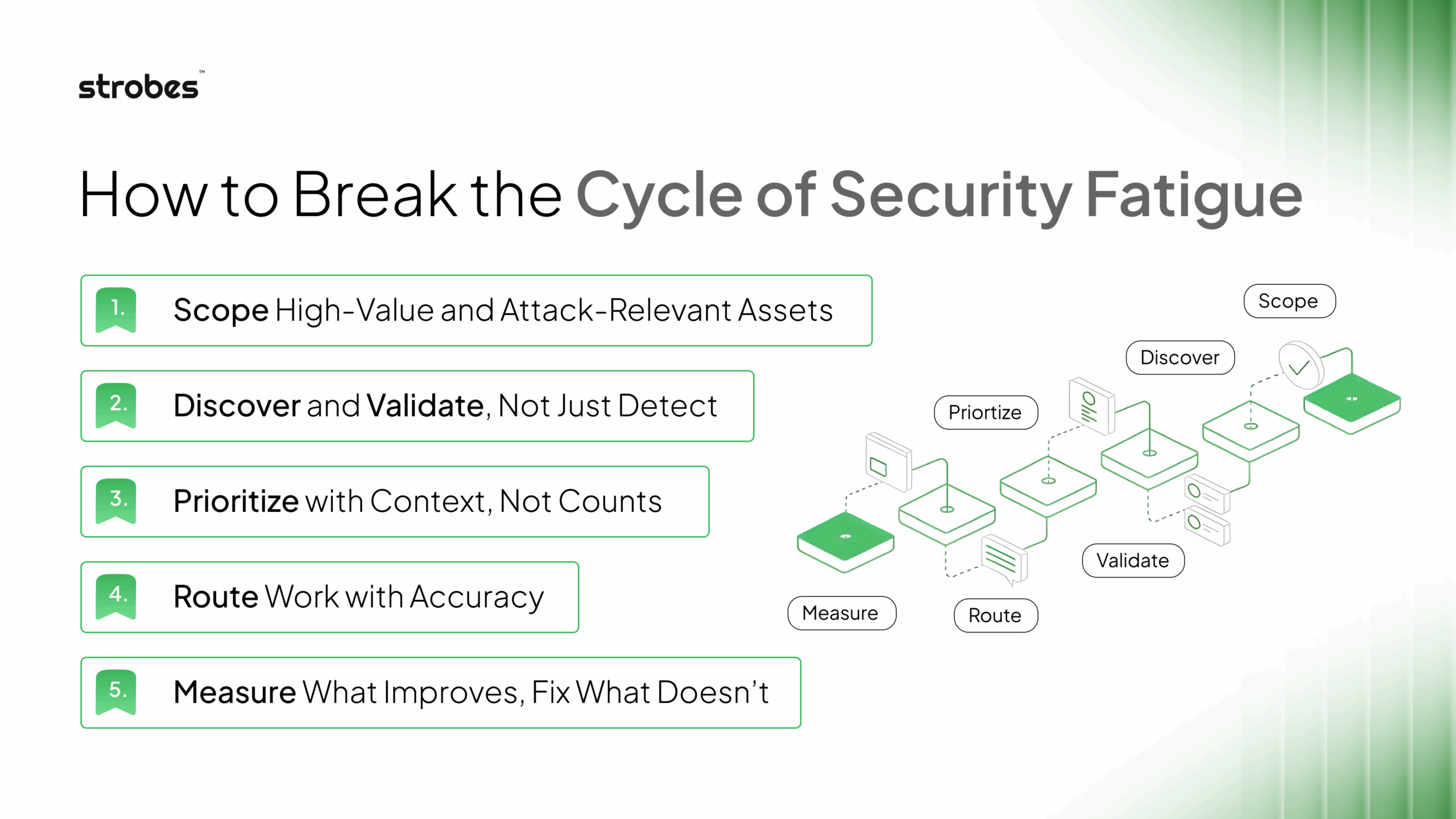
Security fatigue cannot be solved by stacking more tools or dashboards. Each new scanner promises visibility but ends up multiplying alerts. What teams truly need is not more data but a clear sense of priority. They need a way to understand which exposures are real, which are reachable, and which actually threaten the business.
This is where a structured Continuous Threat Exposure Management (CTEM) approach brings a genuine shift in how teams operate. Modern platforms like
Strobes CTEM that follow this model move security from an endless reaction loop to a continuous cycle of awareness, validation, and action. Instead of reacting to noise, teams begin working with clarity and intent.
Here is how that shift looks in practice:
1. Scope High-Value and Attack-Relevant Assets
CTEM begins with the precise scoping of assets that have meaningful attack paths or business impact. Rather than scanning the entire environment, the process narrows focus to components where an exploit would cause operational or reputational damage.
- Asset inventories are automatically synchronized across cloud accounts, CI/CD pipelines, and on-prem systems using integrations with sources like AWS Config, Azure Resource Graph, and Kubernetes manifests.
- Business-critical assets are tagged using metadata such as revenue dependency, data sensitivity, and compliance requirements (for example, PCI-DSS, HIPAA, or SOC 2).
- These tags and rules define which systems feed into the discovery pipeline, ensuring scans focus on the subset of assets that truly expand the organization’s attack surface.
This scoped, risk-aware view prevents unnecessary ingestion of low-value data and eliminates alert fatigue from non-critical systems.
2. Discover and Validate, Not Just Detect
Traditional scanners stop at detection. CTEM extends that process through validation and contextual enrichment. Continuous discovery operates across multiple layers of the attack surface, combining network intelligence, application analysis, and external footprint monitoring.
- External discovery uses DNS resolution, certificate transparency logs, and subdomain enumeration through tools like Censys or Amass.
- Internal discovery leverages authenticated network scans and endpoint telemetry to detect misconfigurations and open services.
- Application analysis integrates with SAST, DAST, and SCA scanners to uncover code-level flaws in both compiled and interpreted languages.
- Every finding is validated against exploit prediction systems such as EPSS and the CISA Known Exploited Vulnerabilities (KEV) catalog to confirm exploitability.
- Duplicates are automatically merged using fingerprinting based on file hashes, URL paths, or API endpoints.
By the time findings reach an analyst, they are already validated, contextualized, and unique.
3. Prioritize with Context, Not Counts
Counting vulnerabilities does not improve security. Knowing which ones have verified exploit chains does. CTEM applies adaptive scoring models that blend exploit intelligence, asset value, and network exposure.
- Risk scoring considers CVSS, EPSS likelihood, asset criticality, exposure reachability, and compensating controls like firewalls or IAM configurations.
- Live threat intelligence feeds (MISP, VirusTotal, Shadowserver) highlight vulnerabilities tied to current exploit campaigns.
- Scores are recalculated dynamically as asset states or threat data change, keeping prioritization accurate and real-time.
This context-driven ranking replaces overwhelming vulnerability lists with a small, focused set of risks that are both exploitable and business-critical.
4. Route Work with Accuracy
Once validated and prioritized, exposures are routed directly to the right owner through integration with existing workflows. CTEM fits into how teams already work rather than forcing them to adapt.
- Native integrations with Jira, ServiceNow, and Azure DevOps ensure tickets are created automatically and linked to asset ownership metadata.
- Rule-based assignment maps issues to repository maintainers, cloud account owners, or system administrators.
- Each ticket includes CVE/CWE references, exploit evidence, and step-by-step remediation details like affected package versions or payload examples.
- Bi-directional sync keeps ticket statuses aligned, ensuring that no task is duplicated or lost.
This automation eliminates manual forwarding, accelerates remediation, and creates accountability with clear ownership.
5. Measure What Improves, Fix What Doesn’t
CTEM functions as a live feedback system. Every stage is measured to help teams learn, optimize, and prevent fatigue from returning.
- MTTR (Mean Time to Remediate) is tracked automatically using timestamps from integrated ticketing systems.
- Validation accuracy measures how often fixes hold after retesting.
- Reopen rates identify recurring exposures in the same assets or repositories.
- Noise ratio shows what percentage of findings were dismissed before assignment.
- Exposure trend analysis reveals whether the organization’s attack surface is expanding or contracting month by month.
These metrics convert subjective “we feel faster” conversations into objective, data-backed insights. Leaders can clearly see where effort delivers measurable results and where process adjustments are needed.
The Measurable Impact of CTEM on Security Fatigue
When Continuous Threat Exposure Management moves from theory to practice, its real value is measured not by how many tools it connects but by how much noise it removes. Security teams begin to notice that fatigue starts to fade when alerts turn into verified, actionable exposures backed by context. Across mature implementations, several measurable shifts appear consistently.
1. Reduced Alert Volume Through Intelligent Correlation
By merging and validating findings across scanners, CTEM eliminates duplicates and false positives before they ever reach an analyst.
- Correlating vulnerability data across scanners like Tenable, Qualys, and Burp Suite removes overlap and normalizes asset context.
- Validation against exploit intelligence databases such as CISA Known Exploited Vulnerabilities (KEV) and EPSS filters out non-exploitable issues.
- Correlation by CVE, asset fingerprint, and service provides a single source of truth instead of fragmented data.
The result is fewer redundant alerts and a noticeable drop in analyst triage workload.
Automation replaces manual routing that often causes confusion and delay.
- Findings are automatically assigned to the correct developer, cloud engineer, or administrator based on asset metadata and repository ownership.
- Integrations with Jira and ServiceNow ensure tickets are automatically created, tracked, and closed with full traceability.
- Enriched tickets include CVE details, exploit references, and payload evidence so owners can act immediately without back-and-forth communication.
Faster routing shortens remediation cycles and helps maintain consistency across distributed teams.
3. Improved Fix Reliability Through Continuous Validation
Repeated work is one of the clearest signs of fatigue. CTEM reduces this by automatically validating every fix before closure.
- Once developers mark an issue as resolved, retesting runs automatically through CI/CD pipelines such as GitHub Actions or Jenkins.
- Validation uses the same payload or exploit that triggered the initial finding, ensuring accuracy.
- Tickets close only after successful validation, with audit logs preserved for compliance.
This process reduces rework and builds confidence that every fix truly mitigates risk.
4. Lower Operational Waste Through Quantified Efficiency Metrics
CTEM surfaces operational inefficiency through measurable indicators.
- Noise ratio highlights the proportion of findings dismissed as false positives before reaching analysts.
- Mean time to remediate (MTTR) shows how efficiently teams are addressing verified exposures.
- Validation accuracy measures how often fixes hold after retesting.
- Exposure trend visualizes whether the organization’s attack surface is expanding or shrinking.
Tracking these metrics helps organizations understand where time is lost and where improvements generate measurable gains.
5. Stronger Security-to-Business Alignment Through Visibility
Fatigue is not only technical but cultural. When leadership can see real progress, confidence in the security program rises.
- Dashboards reveal which business-critical systems contain validated exposures and which have been fully remediated.
- Executives can track risk-weighted backlog or remediation cost per exposure, translating technical outcomes into business value.
- Teams move away from counting vulnerabilities and toward showing how exposure risk is continuously reduced.
That shift gives the work renewed purpose. Fatigue fades because progress becomes visible, measurable, and meaningful.
What a Continuous Exposure Mindset Looks Like in Practice
Adopting a continuous exposure mindset is not about adding new tools. It is about redesigning how telemetry, validation, and automation flow across the environment. Security shifts from scheduled assessments to a live system where exposures are discovered, validated, and prioritized in real time. Layering autonomous penetration testing on top of this validation step pushes the verification further, actively confirming which exposures can be chained into a working exploit before they ever consume an analyst’s attention.
Cloud configurations, application code, and container workloads feed continuously into a unified exposure pipeline that correlates and scores risk based on exploitability, reachability, and asset value. Automated validation ensures that every resolved issue is rechecked immediately after deployment, keeping exposure windows short.
Teams measure success not by the number of tickets closed but by the stability of their exploitable attack surface. Alert noise drops, validation accuracy improves, and decisions become data-driven. Security fatigue fades because focus replaces firefighting.
The future of security belongs to teams that operate with continuous awareness, not periodic visibility. Fatigue ends where context begins.