Most enterprises are not short on security activity. They run scanners, onboard new tools, commission assessments, run internal reviews, and publish regular risk reports. Yet exposure still slips through. Incidents still trace back to issues that were already known. Teams still debate what matters most. And remediation still gets stuck behind ownership, change windows, and competing priorities.
This is exactly why “CTEM adoption” is not a tool rollout. It is an enterprise operating change. CTEM, or Continuous Threat Exposure Management, works only when it becomes a shared way of making exposure decisions across teams that build, run, and maintain systems. When CTEM is adopted across the enterprise, the conversation shifts from “how many issues did we close” to “which exposure paths did we remove.”
This blog explains what CTEM adoption actually means at enterprise scale, why it breaks when handled like a security-only initiative, and how to operationalize it so it sticks. You will also see a clear before-and-after view of what changes once CTEM becomes the default model for exposure decisions.
CTEM as an Operating Model, Not Another Tool Layer
At enterprise scale, CTEM is best understood as an operating model that turns scattered signals into consistent decisions. It connects asset visibility, threat context, prioritization logic, validation, and cross-team execution into a loop that runs continuously.
CTEM is not “more scanning.” It is a new way to decide what deserves action and what can wait, using real-world abuse logic and business impact.
A practical CTEM program answers five questions continuously:
- What is in scope right now, based on what the business runs and what attackers can reach?
- What assets, exposures, and access paths exist inside that scope?
- Which exposures are most likely to be abused, and what would the impact be?
- Which items are real, exploitable, and worth fixing now?
- Who needs to act, and how do we get action without turning everything into meetings?
When CTEM adoption is successful, these questions stop being asked only during audits or incident retros. They become part of daily operations.
The Enterprise Problem CTEM Solves
Most enterprises have achieved a form of visibility. They can scan assets, inventory cloud resources, and collect vulnerability data. But visibility alone does not reduce exposure.
Control requires three things that are usually missing:
- A single shared view of exposure across applications, cloud, and infrastructure
- A consistent prioritization method that multiple teams accept
- A clear path from “identified exposure” to “verified risk removed”
Without these, every team runs its own playbook. You end up with constant activity but inconsistent outcomes.
CTEM adoption is the shift from visibility as a goal to control as the goal.
Why CTEM Adoption Breaks When It Is Treated as a Security-Only Initiative
CTEM touches almost every part of the enterprise because exposure is produced by almost every part of the enterprise.
If CTEM is positioned as “the security team’s new program,” adoption will stall. Not because people disagree with the idea, but because execution depends on teams that do not report into security and do not measure success the same way.
In a large organization, exposure work typically sits across:
- Engineering teams that ship code and own service reliability
- Cloud and platform teams that manage configuration and identity
- Infrastructure teams handling patch cycles and operational stability
- IT and enterprise apps teams managing SaaS and internal platforms
- Risk and compliance teams needing evidence, not opinions
Each group has its own priorities. CTEM adoption requires alignment that respects those priorities instead of trying to override them.
This is the real definition of driving CTEM adoption across the enterprise: making exposure decisions shared, consistent, and operationally realistic across teams that have different objectives.
What “Driving Adoption” Actually Means in an Enterprise Context
Adoption is not a launch date. Adoption is what changes after the launch date.
Driving CTEM adoption means creating conditions where the enterprise naturally uses CTEM outputs to make decisions, week after week, without constant push.
That requires progress on four fronts:
 1) Shared exposure language
1) Shared exposure language
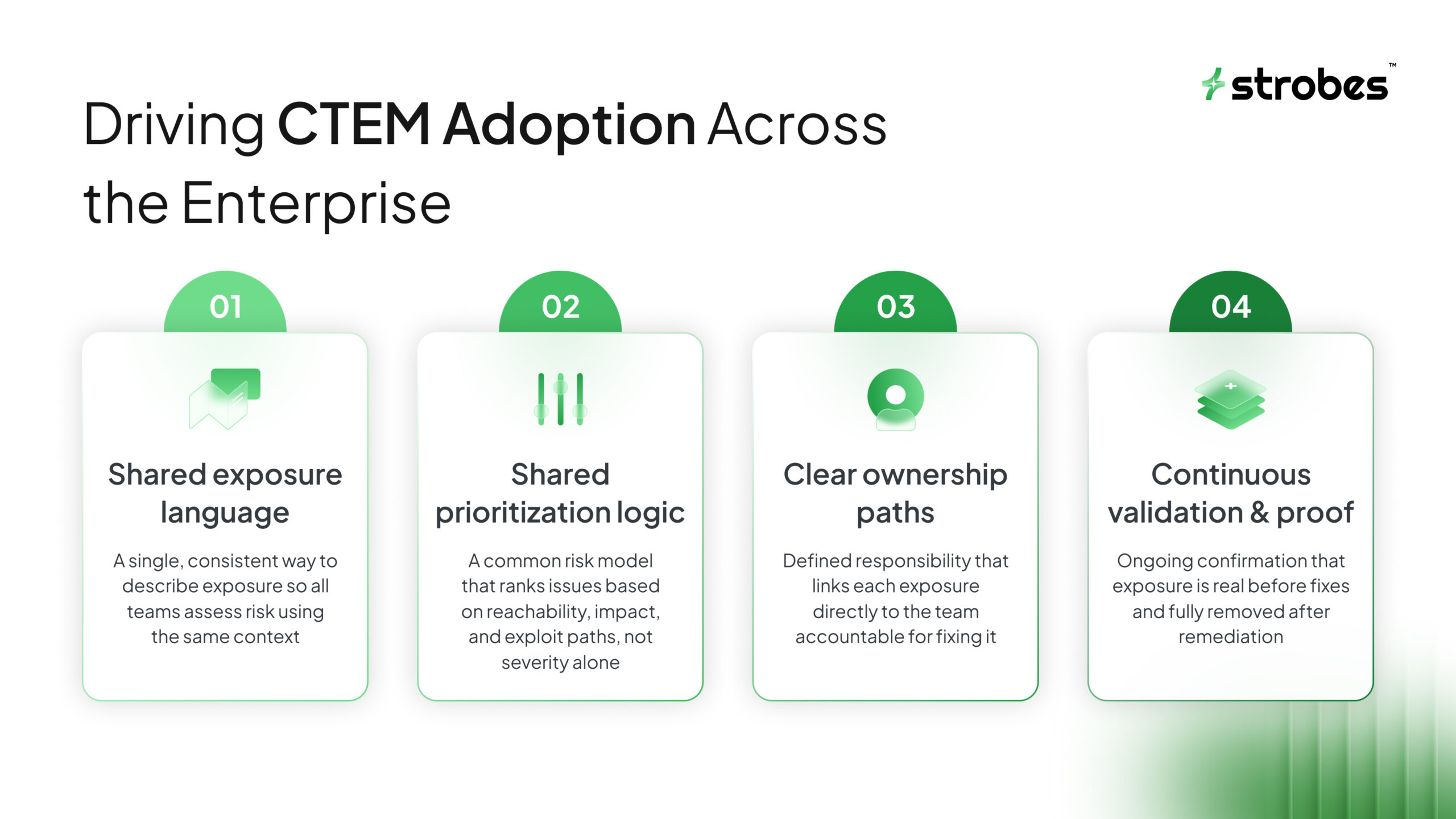 1) Shared exposure language
1) Shared exposure languageIf one team says “Critical” and another team says “not reachable,” you do not have alignment. You have friction.
A CTEM-aligned organization uses shared terms such as:
- Reachability from external networks
- Privilege impact and access expansion
- Lateral movement potential
- Business workflow impact
- Data sensitivity and service criticality
These terms cut across tools and teams.
2) Shared prioritization logic
If teams do not trust the prioritization model, they will revert to their own queues.
CTEM adoption requires a prioritization method that explains “why this now” in a way that is clear to engineering and operations.
3) Clear ownership paths
The enterprise must know who owns an exposure and who approves changes. If ownership is unclear, CTEM becomes another reporting exercise.
4) Continuous validation and proof
If fixes are assumed and not verified, exposure quietly returns. CTEM adoption requires a habit of verifying that risk was actually removed.
Building the Foundation for Enterprise-Wide CTEM Adoption
CTEM cannot run on messy inputs. The foundation matters more than the dashboard.
Unified asset context
Enterprises often have “inventories,” but they are fragmented. One tool knows cloud resources. Another knows endpoints. Another knows applications. Another knows SaaS. They rarely connect cleanly.
CTEM needs a unified asset picture that answers:
- What assets exist and which ones matter most?
- Which services connect to which systems?
- Which identity and access paths exist between them?
- Which assets are internet-facing, and which are internal only?
This does not require perfection on day one. It requires a working baseline that improves continuously.
Pointers that matter at this stage:
- Assign an asset owner for every critical system, even if the ownership is shared.
- Define “critical” using business workflows, not just technical labels.
- Track dependency relationships for key services, at least at a high level.
Normalized exposure data
Most enterprises have duplicates. The same issue appears in multiple tools. Slight variations produce multiple tickets. Multiple teams work the same problem unknowingly.
CTEM adoption improves when exposure data is normalized into a single view where:
- duplicate findings are grouped
- related issues are correlated by asset and root cause
- repeated noise is minimized
This reduces arguments and accelerates action.
Trust in prioritization signals
Trust is built when the model is explainable.
If the prioritization output is “this is top risk because the tool says so,” adoption will fail. If the output is “this is top risk because it is reachable, exploitable, and impacts a critical workflow,” adoption grows.
Moving from Severity-Based Fixing to Exposure-Based Action
Severity is a useful input, but a weak decision-maker.
Two realities are true in most enterprises:
- Many high-severity issues are hard to abuse in your specific environment.
- Some lower-severity issues become serious because of where they sit and how they connect.
CTEM adoption replaces severity-first queues with exposure-first decisions.
A strong exposure-first decision considers:
- Reachability: Can an attacker access it from outside, or through common entry points?
- Exploit conditions: Is there a known practical exploit path, or is it theoretical?
- Privilege impact: Does it enable privilege increase, token theft, or access expansion?
- Blast radius: If abused, how far can it spread across connected systems?
- Workflow impact: Does it touch revenue, customer access, or critical operations?
- Existing controls: Are compensating controls actually effective in this case?
This method produces fewer “urgent” items, but higher-quality urgency.
That is the point.
Enterprise Before CTEM Adoption vs Enterprise After CTEM Adoption
| Aspect | Enterprise Before CTEM Adoption | Enterprise After CTEM Adoption |
| Overall approach | Exposure management runs as disconnected activities happening in parallel across teams and tools. | Exposure management runs as a consistent, enterprise-wide decision model that stays active over time. |
| Data collection | Scan data is gathered from multiple tools and stored in separate systems with limited correlation. | Asset and exposure signals are brought together into a shared view with consistent context. |
| Prioritization method | Priorities are driven mainly by severity ratings, SLA targets, or pressure from stakeholders. | Priorities are driven by reachability, exploit paths, and impact on critical workflows. |
| Backlog quality | Duplicate issues inflate backlogs and make it difficult to understand what truly matters. | Exposure lists are cleaned and deduplicated, making high-impact issues easier to identify. |
| Ownership clarity | Ownership debates slow remediation because responsibility is unclear or disputed. | Ownership and routing are tied directly to asset responsibility, reducing friction. |
| Validation of fixes | Issues are often marked fixed without confirming that exposure is actually removed. | Validation confirms that exposure has been eliminated, not just closed in a system. |
| Reporting focus | Reports emphasize counts and activity because they are easy to measure. | Reporting focuses on exposure reduction and risk concentration over time. |
| Outcome | The organization is active but operates without a shared exposure model. | The organization moves from issue volume management to exposure reduction management. |
Operationalizing CTEM Across Day-to-Day Workflows
This is where most CTEM programs collapse. People agree with the idea, but the enterprise does not change how work is done.
CTEM adoption becomes real only when it plugs into existing operational workflows. That means CTEM outputs must show up where work already happens.
A practical operating model looks like this:
Routing exposure insights into existing work systems
CTEM should not create a parallel world of tasks and approvals. It should feed enriched exposure items into the tools teams already use for work tracking and change management.
Pointers that make this work:
- Use one consistent template for exposure tickets across teams.
- Include reachability, impact, and exploit conditions in the ticket, not just CVE and severity.
- Include the specific asset and owner mapping in the ticket so it does not bounce.
Clear ownership without adding friction
Ownership should follow the asset. If a service is owned by a product team, remediation should route there. If a cloud account is owned by a platform team, configuration remediation should route there.
CTEM adoption becomes smoother when:
- ownership is defined for critical systems first
- ownership definitions are published in a simple internal reference
- escalation paths are clear for orphan assets
Timelines aligned to exposure, not generic SLAs
Generic SLAs fail in enterprise environments because they ignore operational reality.
Exposure-based timelines are more realistic because they vary based on risk concentration.
Example of how CTEM changes timelines in practice:
- Highly reachable exposure on a critical workflow gets priority and a short window.
- Low reachability exposure on a non-critical system can be scheduled into routine maintenance.
- Exposure that enables privilege increase gets priority even if the severity rating is not the highest.
This reduces wasted urgency and increases real risk reduction.
Tracking progress based on exposure reduction
If teams are measured only on closure counts, they will chase easy fixes and ignore structural exposure.
Better progress tracking includes:
- number of reachable exposure paths removed
- reduction in exposure concentration across critical assets
- time to validate fixes for high-impact exposure
- reduction in repeat exposure caused by configuration drift
These show whether CTEM adoption is working, not whether people are busy.
Measuring Success Without Falling Back Into Noise
Most enterprise programs get trapped by metrics. Either there are too many metrics, or the wrong metrics become the goal.
CTEM adoption should be measured using a small set of outcome-based metrics that are hard to game.
Strong CTEM metrics include:
- Reachable exposure count on critical assets
This tells you whether the most important assets are safer over time. - Exposure concentration trend
If risk keeps clustering in the same systems, you have a structural problem, not a workload problem. - Time to validate high-impact fixes
This tells you whether the organization can move fast when it matters. - Repeat exposure rate
If the same exposure types return, you need stronger engineering controls and better change discipline.
These metrics work because they point to outcomes, not activity.
What Changes When CTEM Is Adopted Across the Enterprise
When CTEM adoption takes hold, the enterprise starts to behave differently.
Risk conversations become shorter because context is shared. Priority debates reduce because the model is explainable. Backlogs shrink because duplication and low-impact items stop consuming attention. Teams fix fewer issues overall, but the fixes matter more. Reporting becomes easier because outcomes are clearer.
Most importantly, exposure management becomes predictable. Instead of a constant scramble driven by tool outputs and quarterly pressure, the enterprise runs a continuous loop that steadily reduces reachable risk.
That is what the title promises. That is what CTEM adoption delivers when it is done as an operating change, not a tool change.
Conclusion
Driving CTEM adoption across the enterprise is not about chasing maturity models or adding more layers of reporting. It is about restoring control over exposure in environments that move faster than traditional security processes were built to handle. When exposure decisions are fragmented, risk accumulates quietly. When those decisions are shared, contextual, and continuous, exposure becomes manageable.
Enterprises that succeed with CTEM do not fix everything. They fix what matters. They move away from volume-driven backlogs and toward clarity-driven action. Asset context replaces guesswork. Exposure paths replace severity-only queues. Validation replaces assumption. Over time, this creates consistency. Teams stop reacting to noise and start reducing real exposure in a way that holds up as the organization grows.
Strobes Security helps enterprises operationalize CTEM as a continuous practice, not a periodic exercise. By unifying exposure signals across applications, cloud, and production environments, reducing duplication, and prioritizing based on real-world risk context, Strobes enables teams to align faster and act with confidence.
Start by exploring how Strobes enables continuous exposure management across the enterprise and see what changes when CTEM becomes the way exposure decisions are actually made.





