OWASP Top 10 for LLMs: Key Risks & Mitigation Strategies
Likhil ChekuriDecember 16, 202420 min read
Table of Contents
Authors
L
Likhil Chekuri
Share
The rapid advancement of AI, particularly in large language models (LLMs), has led to transformative capabilities in numerous industries. However, with great power comes significant security challenges. The OWASP Top 10 for LLMs addresses evolving threats. This article explores what's new, what’s changed, and key priorities for securing AI systems.
Although these changes were finalized in late 2024, OWASP Core Team Contributors designated the list for 2025, signalling their confidence in its relevance over the coming months. The updated list emphasizes a refined understanding of existing risks and includes new vulnerabilities identified through real-world exploits and advancements in LLM usage.
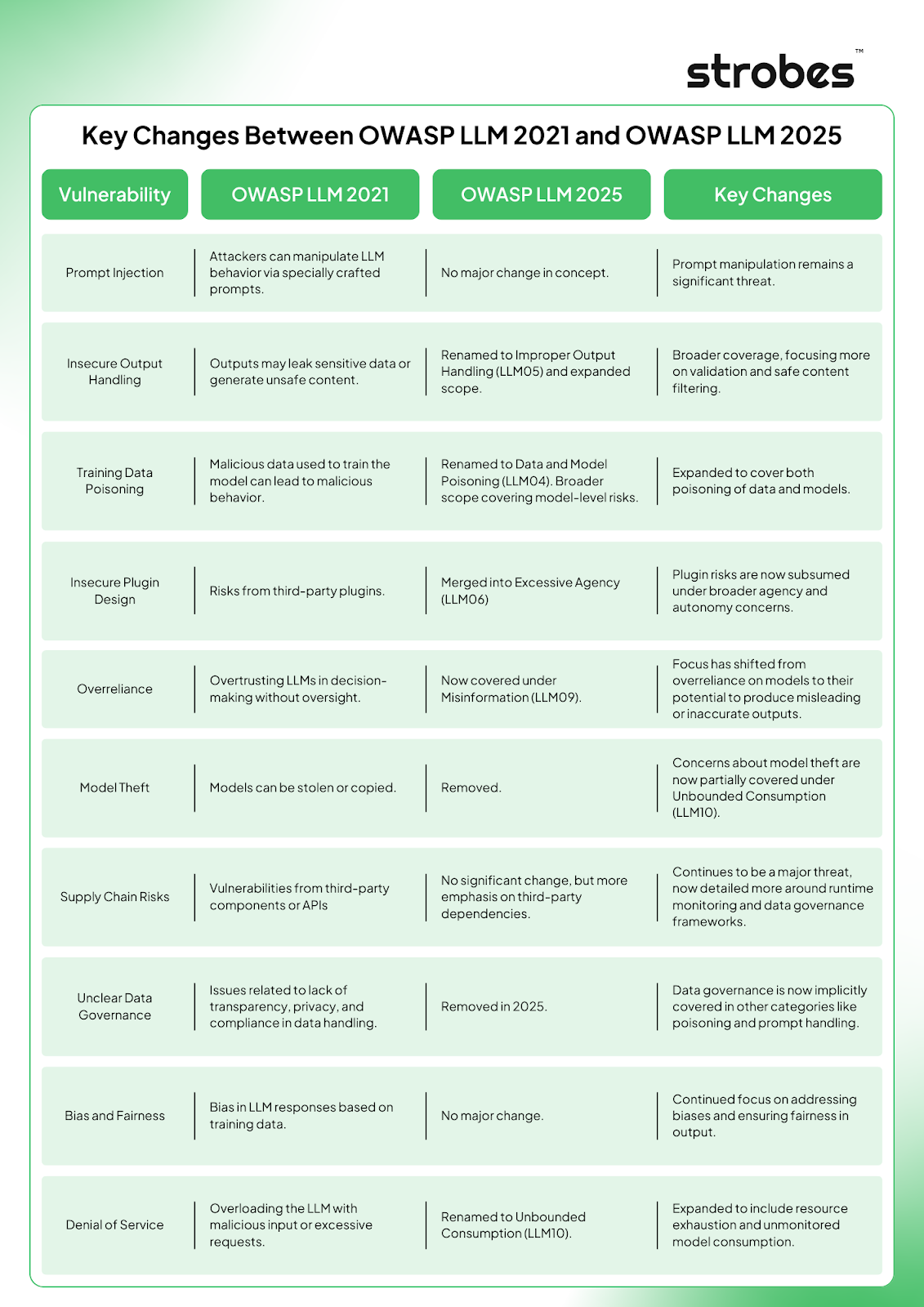
Key Changes Between OWASP LLM 2021 and OWASP LLM 2025
Let's dive deep into the OWASP Top 10 for LLMs risks in 2025 and explore key security challenges and mitigation strategies:
LLM01:2025 Prompt Injection
APrompt Injection Vulnerability occurs when user inputs manipulate an LLM’s behavior or output in unintended ways, even if the inputs are invisible to humans. These vulnerabilities stem from how models process prompts, potentially causing them to violate guidelines, generate harmful content, or enable unauthorized access. Techniques like Retrieval Augmented Generation (RAG) and fine-tuning help improve output accuracy but don't fully prevent prompt injections.
Prompt injection involves altering LLM behavior through specific inputs, while jail breaking is a type of prompt injection that bypasses safety protocols. Mitigation strategies include system prompt safeguards and input handling, but preventing jailbreaking requires ongoing updates to the model’s training and safety measures.
Prevention and Mitigation Strategies
Prompt injection vulnerabilities arise due to the inherent nature of generative AI. Given the probabilistic operation of these models, achieving complete prevention remains uncertain. However, the following strategies can significantly reduce the risk and impact:
Constrain Model Behaviour - Set explicit guidelines in the system prompt regarding the model's role, capabilities, and boundaries. Ensure strict context adherence, limit responses to defined tasks or topics, and instruct the model to disregard any attempts to alter core instructions.
Define and Validate Expected Outputs - Establish clear output formats and request detailed reasoning or citations. Use deterministic code to validate that outputs conform to these specifications.
Implement Input and Output Filtering - Identify sensitive categories and create rules to detect and manage such content. Apply semantic filters and string-checking to screen for unauthorized material. Use the RAG Triad (Relevance, Groundedness, Answer Quality) to assess responses and detect potentially harmful outputs.
Enforce Privilege Control and Least Privilege Access - Provide applications with dedicated API tokens for extended functionality. Manage these functions within code rather than exposing them to the model. Limit the model’s access rights to the minimum necessary for its operations.
Introduce Human Approval for High-Risk Actions - Incorporate human-in-the-loop controls for sensitive operations to prevent unauthorized activities.
Segregate and Label External Content - Clearly separate and label untrusted content to minimize its influence on user prompts.
Conduct Adversarial Testing and Simulations - Regularly perform penetration tests and attack simulations. Treat the model as an untrusted entity to assess the effectiveness of trust boundaries and access controls.
LLM02:2025 Sensitive Information Disclosure
Sensitive information, such as PII, financial details, or proprietary data, can pose risks to both LLMs and their application contexts. These risks include exposing sensitive data, privacy violations, and intellectual property breaches through model outputs. Users must be cautious about sharing sensitive data with LLMs, as it might be inadvertently disclosed.
To mitigate these risks, LLM applications should sanitize data to prevent sensitive input from being used in training, offer opt-out options through clear Terms of Use, and implement system-level restrictions on the data types the model can return. However, these measures are not foolproof and may be bypassed through techniques like prompt injection.
Prevention and Mitigation Strategies:
1. Sanitization
Apply Data Sanitization Techniques - Implement strategies to scrub or mask sensitive information before using data in training, ensuring personal or confidential details are excluded from the model.
Strengthen Input Validation - Adopt robust input validation processes to identify and filter harmful or sensitive data inputs, preventing potential risks to the model.
2. Access Controls
Enforce Minimal Access Policies - Restrict access to sensitive data based on the principle of least privilege, granting users or processes only the access essential for their function.
Limit External Data Access - Restrict model interactions with external data sources and ensure secure runtime data management to prevent unintended leaks.
3. Federated Learning and Privacy
Leverage Federated Learning - Train models using decentralized data across multiple servers or devices to reduce the risks associated with centralized data storage.
Adopt Differential Privacy Measures - Introduce techniques like adding noise to data or outputs to obscure individual data points and safeguard privacy.
4. User Education and Transparency
Train Users on Safe LLM Interactions - Provide clear instructions to users about avoiding sensitive data input and offer best practices for secure engagement with models.
Promote Transparent Data Policies - Clearly outline how data is collected, used, retained, and deleted. Offer users the ability to opt out of training data inclusion.
5. Secure System Configuration
Protect System Settings - Prevent users from accessing or altering the system’s initial configurations to avoid exposing internal settings.
Follow Security Misconfiguration Best Practices - Refer to standards like “OWASP API8:2023 Security Misconfiguration” to mitigate risks of sensitive data exposure through error messages or misconfigured settings.
6. Advanced Privacy Techniques
Utilize Homomorphic Encryption - Enable secure data processing by adopting homomorphic encryption, which ensures data confidentiality even during model computations.
Implement Tokenization and Redaction - Apply tokenization techniques to preprocess sensitive information. Use pattern matching to detect and redact confidential data before processing.
LLM03:2025 Supply Chain
LLM supply chains face unique vulnerabilities affecting training data, models, and deployment platforms, leading to risks like biased outputs, security breaches, or failures. Unlike traditional software, ML risks include tampering or poisoning attacks on third-party pre-trained models and data.
The use of open-access LLMs, fine-tuning methods like LoRA and PEFT, and platforms like Hugging Face heighten supply-chain risks. On-device LLMs further expand the attack surface. These risks overlap with "LLM04 Data and Model Poisoning," but focus specifically on the supply-chain dimension. A simple threat model is available for further insight.
Prevention and Mitigation Strategies
1. Strengthen Supplier Validation
Vendor Screening: Establish rigorous screening processes to assess the security posture of suppliers, focusing on their practices for securing training data and model weights.
Third-Party Audits: Conduct regular security audits of third-party vendors and partners to ensure compliance with industry standards and your organization’s security policies.
2. Implement Secure Model Integration
Dependency Isolation: Use containerization or isolated environments to integrate third-party models, minimizing the risk of unwanted data leaks or malicious activity.
Version Control: Track and validate model versions using cryptographic hash functions to ensure no tampering occurs during updates or deployments.
3. Enhance Data Supply Chain Integrity
Training Data Verification: Employ methods like provenance tracking and integrity checks to ensure that training datasets have not been poisoned or tampered with.
Input Sanitization: Validate and sanitize all inputs before they interact with LLMs to prevent injection attacks via malicious payloads.
4. Monitor for Malicious Model Behavior
Behavioral Analysis: Continuously monitor deployed LLMs for unusual outputs or behaviors that might indicate tampering.
Threat Intelligence Feeds: Subscribe to security feeds to stay updated on known vulnerabilities or exploits affecting supply chain elements.
5. Enforce Access Controls
Principle of Least Privilege: Limit access to supply chain components to only those roles that require it, reducing the risk of unauthorized changes.
Role-Based Permissions: Implement robust role-based access controls (RBAC) for interacting with LLM assets.
6. Secure Model Update Mechanisms
Code Signing: Ensure all model updates and patches are digitally signed and verified before deployment.
Change Management: Maintain a strict change management process for model updates to prevent the introduction of vulnerabilities.
7. Conduct Continuous Risk Assessments
Supply Chain Mapping: Regularly assess and document your LLM’s supply chain to identify potential vulnerabilities.
Penetration Testing: Simulate attacks on the supply chain to uncover weaknesses before adversaries exploit them.
8. Prepare for Incident Response
Incident Playbooks: Develop and test incident response playbooks specifically for supply chain attacks on LLMs.
Backup and Recovery: Maintain secure backups of models, training datasets, and metadata to ensure quick recovery in case of a breach.
LLM04:2025 Data and Model Poisoning
Data poisoning occurs when pre-training, fine-tuning, or embedding datasets are deliberately manipulated to introduce vulnerabilities, biases, or backdoors. This interference can compromise a model's security, performance, or ethical alignment, resulting in harmful outputs or diminished functionality. Common risks include reduced model accuracy, generation of biased or inappropriate content, and exploitation of connected systems.
This threat can arise at various stages of the LLM lifecycle:
Pre-training: Learning from broad datasets.
Fine-tuning: Customizing models for specific tasks.
Embedding: Translating text into numerical vectors.
Identifying vulnerabilities at each stage is crucial, as data poisoning is a form of integrity attack that undermines a model’s ability to make reliable predictions. The risk intensifies with external data sources, which may harbor unverified or malicious content.
Additionally, models distributed via shared repositories or open-source platforms face broader risks, such as malware introduced through malicious pickling. This technique embeds harmful code that activates when the model is loaded. Poisoning can also enable backdoors, which remain dormant until triggered by specific inputs. These hidden mechanisms are difficult to detect and can covertly transform the model’s behavior, effectively turning it into a "sleeper agent."
Prevention and Mitigation Strategies
1. Data Security and Validation
Use Trusted Data Sources: Source training and fine-tuning datasets only from verified, reputable sources to minimize exposure to tampered or malicious data.
Data Validation Pipelines: Implement automated pipelines to sanitize and validate incoming data, removing duplicates, corrupted entries, or anomalies.
Metadata Verification: Cross-check metadata and provenance of datasets to ensure authenticity.
2. Monitoring and Auditing
Continuous Data Monitoring: Monitor data usage and changes, flagging any unexpected or unauthorized modifications.
Access Controls: Restrict access to training datasets and logs to minimize tampering opportunities.
Audit Logs: Maintain detailed logs of data access and model updates for forensic analysis in case of suspected poisoning attempts.
3. Model Robustness
Defensive Training: Include adversarial training techniques to expose models to controlled, adversarial examples, improving their resilience to poisoned inputs.
Layered Learning: Use transfer learning from pre-trained models less prone to poisoning, reducing reliance on sensitive data.
4. Poison Detection Techniques
Anomaly Detection: Deploy machine learning models to detect irregularities in data distributions or inputs during training.
Behavioral Testing: Regularly test model outputs for unexpected or biased behaviors resulting from potential poisoning.
Canary Data: Introduce synthetic, innocuous data into datasets to monitor model responses and detect poisoning early.
5. Access and Update Controls
Model Checkpoints: Save periodic model states to revert to a trusted version in case of poisoning detection.
Controlled Fine-Tuning: Implement strict protocols for when and how models can be updated, limiting unauthorized fine-tuning.
Access Restrictions: Limit access to model architecture and training pipelines using role-based access control (RBAC).
6. Regular Model Evaluations
Third-Party Assessments: Engage external experts to audit models and datasets periodically for signs of poisoning.
Benchmark Testing: Compare model performance against established benchmarks to identify deviations caused by poisoning.
7. Use Synthetic and Augmented Data
Synthetic Data Generation: Supplement datasets with synthetic data created using trusted algorithms to reduce dependency on potentially compromised real-world data.
Data Augmentation: Randomize and augment data samples to make poisoning attacks less effective.
8. Leverage AI-Specific Security Tools
Poisoning Detection Software: Use tools specifically designed to detect and mitigate AI model poisoning.
Continuous Threat Modeling: Integrate AI security tools that dynamically assess risks to datasets and models.
9. Stakeholder Collaboration
Community Feedback: Collaborate with external researchers and stakeholders for early identification of potential poisoning patterns.
Threat Intelligence Sharing: Engage in shared intelligence networks to stay updated on evolving threats related to LLM poisoning.
10. Incident Response Plan
Mitigation Playbook: Develop a step-by-step guide for responding to identified data or model poisoning attacks.
Rollback Mechanisms: Establish procedures to revert to pre-attack states quickly while maintaining continuity.
Continuous Improvement: Post-incident analysis should feed into refining prevention and mitigation measures.
LLM05:2025 Improper Output Handling
Improper Output Handling refers to the failure to properly validate, sanitize, and manage the outputs generated by large language models (LLMs) before they are passed to other components and systems. Since LLM outputs can be influenced by user input, this issue is similar to giving users indirect access to additional system functionalities.
Unlike Overreliance, which focuses on concerns about excessive dependence on LLM outputs' accuracy and appropriateness, Improper Output Handling deals specifically with the outputs before they are passed on. Exploiting an Improper Output Handling vulnerability can lead to issues like XSS and CSRF in web browsers, or SSRF, privilege escalation, and remote code execution in backend systems. Conditions that increase the risk of this vulnerability include:
The application granting excessive privileges to the LLM, allowing for privilege escalation or remote code execution.
Vulnerabilities to indirect prompt injection attacks, enabling attackers to access privileged user environments.
Inadequate validation of inputs by third-party extensions.
Lack of proper output encoding for various contexts (e.g., HTML, JavaScript, SQL).
Insufficient monitoring and logging of LLM outputs.
Absence of rate limiting or anomaly detection for LLM usage.
Prevention and Mitigation Strategies
Treat the model as a user, adopting a zero-trust model, and ensure proper input validation for any responses from the model to backend functions.
Follow the OWASP ASVS (Application Security Verification Standard) guidelines to implement effective input validation and sanitization.
Encode the model’s output before delivering it to users to prevent unintended code execution, such as JavaScript or Markdown. OWASP Top 10 for LLMs ASVS offers detailed guidance on output encoding.
Use context-specific output encoding, adjusting based on how the LLM output will be utilized (e.g., HTML encoding for web content, SQL escaping for database queries).
Always use parameterized queries or prepared statements for database interactions that involve LLM-generated content.
Implement strict Content Security Policies (CSP) to reduce the risk of XSS attacks from LLM-generated content.
Set up robust logging and monitoring systems to identify unusual patterns in LLM outputs, which could signal potential exploitation attempts.
LLM06:2025 Excessive Agency
An LLM-based system is often designed with a certain level of agency, allowing it to execute actions through functions or interact with other systems via extensions (also known as tools, skills, or plugins, depending on the vendor).
These extensions may be selected by the system based on input prompts or outputs from the LLM, with an agent sometimes responsible for determining which extension to invoke. In agent-based systems, repeated calls to the LLM are made, with outputs from prior invocations used to guide subsequent actions.
Excessive Agency is a vulnerability that allows harmful actions to occur in response to unexpected, ambiguous, or manipulated outputs from the LLM, regardless of the cause behind the malfunction. Common triggers for this vulnerability include:
Hallucination or confabulation resulting from poorly-engineered benign prompts or a subpar model.
Prompt injection, either direct or indirect, by a malicious user, a previous invocation of a compromised extension, or, in multi-agent systems, a compromised peer agent.
The root causes of Excessive Agency often stem from:
Excessive functionality
Excessive permissions
Excessive autonomy
Excessive Agency can have a wide range of negative impacts on confidentiality, integrity, and availability, depending on the systems that the LLM-based application can interact with.
Prevention and Mitigation Strategies for Excessive Agency
To prevent Excessive Agency in LLM-based systems, consider the following strategies:
Limit Extension Use Restrict the number of extensions available to LLM agents, allowing only those that are essential for the system. For instance, if URL fetching is not required, ensure the LLM agent cannot access such functionality.
Minimize Extension Functionality Keep the functionality within each extension as minimal as possible. For example, if an extension is used to summarize emails, ensure it only has permission to read emails and does not include capabilities like deleting or sending messages.
Avoid Open-Ended Extensions Use extensions with clearly defined and limited functions, avoiding those with broad or open-ended capabilities (e.g., shell commands or URL fetching). For example, instead of using a shell command extension to write files, create a specific file-writing extension that focuses only on that task.
Limit Extension Permissions Grant extensions only the minimum necessary permissions to interact with other systems. For example, if an LLM-based system accesses a product database for recommendations, restrict it to read-only access for the relevant tables and deny permission to modify data.
Operate Extensions in User Context Ensure that actions taken by LLM extensions on behalf of a user are executed with that user's specific authorization and the minimum required privileges. For instance, a user should authenticate through OAuth with limited access when an LLM extension reads their code repository.
Require User Approval Implement human-in-the-loop controls to obtain user approval for high-impact actions before they are executed. For example, an LLM system posting on social media on a user’s behalf should include a step where the user must approve the content before it is published.
Enforce Complete Mediation Rather than relying on LLM agents to determine if an action is authorized, enforce authorization checks in downstream systems. This ensures that all requests are validated according to security policies before being processed.
Sanitize Inputs and Outputs Follow secure coding best practices, such as OWASP Top 10 for LLMs guidelines, with a focus on input sanitization. Incorporate Static Application Security Testing (SAST) and Dynamic Application Security Testing (DAST) into the development process to identify vulnerabilities early.
While not preventing Excessive Agency directly, the following actions can help mitigate potential damage:
Log and Monitor Activities Continuously monitor LLM extensions and downstream systems to detect undesirable actions early and respond promptly.
Implement Rate Limiting Apply rate limiting to restrict the number of actions an LLM extension can perform within a specified timeframe, allowing time for detection and intervention before significant damage occurs.
LLM07:2025 System Prompt Leakage
System prompt leakage occurs when instructions guiding LLMs inadvertently expose sensitive information like credentials or permissions. These prompts are not secure and should never store sensitive data.
The primary risk isn’t the disclosure of the prompt itself but underlying issues like weak session management, improper privilege separation, or bypassing system guardrails. Attackers can often infer prompt constraints through system interaction, even without direct access.
To mitigate risks, avoid embedding sensitive data in prompts and focus on robust security practices at the application level.
Prevention and Mitigation Strategies:
Separate Sensitive Data from System Prompts Keep sensitive information (e.g., API keys, authentication credentials, database names, user roles, and permission structures) out of system prompts. Store and manage such data in external systems that the LLM cannot directly access.
Avoid Dependence on System Prompts for Strict Behavior Control System prompts are vulnerable to attacks, such as prompt injections, which can modify their instructions. Instead of relying on them for critical behavior enforcement, use external systems for tasks like detecting and preventing harmful content.
Establish Independent Guardrails Implement guardrails outside the LLM to monitor and enforce compliance with desired behavior. While training the model to avoid certain actions, such as revealing its system prompts, may help, it’s not foolproof. An external mechanism that validates the LLM's output provides more reliability than relying solely on system prompt instructions.
Enforce Security Controls Independently from the LLM Critical security functions like privilege separation and authorization checks should not depend on the LLM. These controls must be deterministic and auditable, which current LLMs cannot guarantee. For tasks requiring varying levels of access, use multiple agents, each configured with minimal privileges necessary for their specific roles.
LLM08:2025 Vector and Embedding Weaknesses
Vectors and embeddings pose notable security challenges in systems that implement Retrieval-Augmented Generation (RAG) with Large Language Models (LLMs). Vulnerabilities in their generation, storage, or retrieval processes can be exploited to inject harmful content, alter model outputs, or gain unauthorized access to sensitive data—whether through intentional attacks or accidental misuse.
RAG is a technique designed to boost the performance and contextual accuracy of LLM applications. It integrates pre-trained language models with external knowledge sources, relying on vectors and embeddings as core mechanisms to enable this enhancement.
Prevention and Mitigation Strategies
Access Control and Permissions Enforce fine-grained access controls with permission-aware vector and embedding storage. Secure datasets in the vector database through logical and access-based partitioning to prevent unauthorized access across user groups or classes.
Data Validation and Source Authentication Set up robust validation pipelines for knowledge sources. Conduct regular audits to ensure the integrity of the knowledge base, identifying hidden codes or signs of data poisoning. Accept inputs exclusively from verified and trusted sources.
Data Combination and Classification When merging datasets from various sources, conduct a thorough review to maintain integrity. Use tagging and classification within the knowledge base to manage access and prevent mismatches.
Monitoring and Logging Implement immutable logging for retrieval activities, enabling quick detection and response to unusual or suspicious behavior.
LLM09:2025 Misinformation
Misinformation generated by LLMs represents a critical vulnerability for applications that depend on these models. This occurs when LLMs produce false or misleading information that appears credible, potentially leading to security risks, reputational harm, and legal exposure.
A primary source of misinformation is hallucination—when an LLM generates content that seems accurate but is entirely fabricated. Hallucinations arise as models fill gaps in their training data based on statistical patterns, without actual comprehension of the content. As a result, they may provide answers that sound plausible but lack any factual basis. In addition to hallucinations, biases embedded in the training data and incomplete information further contribute to misinformation.
Another challenge is overreliance, where users place undue trust in LLM-generated content without verifying its accuracy. This overconfidence amplifies the risks of misinformation, as unverified outputs may be integrated into critical decisions or workflows, compounding errors and increasing potential harm.
Prevention and Mitigation Strategies
Retrieval-Augmented Generation (RAG) Leverage RAG to improve the accuracy of outputs by retrieving relevant, verified information from trusted databases during response generation. This reduces the likelihood of hallucinations and misinformation.
Model Fine-Tuning Optimize models with fine-tuning or embedding techniques to enhance output quality. Approaches like parameter-efficient tuning (PET) and chain-of-thought prompting can help minimize inaccuracies.
Cross-Verification and Human Oversight Encourage users to verify LLM-generated outputs against reliable external sources. Establish human oversight and fact-checking processes for critical or sensitive content, ensuring reviewers are adequately trained to avoid overreliance on AI.
Automated Validation Implement automatic validation mechanisms to ensure the reliability of outputs, particularly in high-stakes scenarios.
Risk Communication Identify and communicate the risks of LLM-generated content, including potential inaccuracies. Clearly outline these limitations to users to promote informed decision-making.
Secure Coding Practices Adopt secure coding protocols to prevent vulnerabilities stemming from incorrect AI-generated code suggestions.
User Interface Design Create user interfaces and APIs that promote responsible LLM usage. Include content filters, label AI-generated outputs clearly, and inform users about limitations in reliability and accuracy. Specify constraints for the intended use cases.
Training and Education Offer comprehensive training on LLM limitations, emphasizing the need for independent content verification and critical thinking. In specialized fields, provide domain-specific training to help users assess AI outputs effectively within their area of expertise.
LLM10:2025 Unbounded Consumption
Unbounded Consumption refers to a situation where a Large Language Model (LLM) generates outputs based on input queries without proper limits. Inference, a vital function of LLMs, involves applying learned patterns and knowledge to produce relevant responses or predictions.
Certain attacks aim to disrupt services, drain financial resources, or steal intellectual property by replicating a model's behavior. These attacks rely on a common vulnerability to succeed.
Unbounded Consumption occurs when an LLM application permits excessive and uncontrolled inferences, leading to risks such as denial of service (DoS), financial loss, model theft, and service degradation. The significant computational demands of LLMs, particularly in cloud environments, make them susceptible to resource exploitation and unauthorized access.
Prevention and Mitigation Strategies:
1. Input Validation Enforce strict input validation to ensure data does not exceed acceptable size limits.
2. Limit Exposure of Logits and Logprobs Limit or obscure the exposure of logit_bias and logprobs in API responses, revealing only essential information while protecting detailed probabilities.
3. Rate Limiting Enforce rate limits and quotas to control the number of requests a single source can make within a defined timeframe.
4. Resource Allocation Management Continuously monitor and adjust resource allocation to prevent any individual request or user from overusing system resources.
5. Timeouts and Throttling Implement timeouts and throttle resource-intensive tasks to avoid prolonged resource consumption.
6. Sandbox Techniques Limit the LLM's access to network resources, internal services, and APIs. This is vital for mitigating insider risks and side-channel attacks by controlling access to data and resources.
7. Comprehensive Logging, Monitoring, and Anomaly Detection Monitor resource usage and implement logging systems to identify and respond to abnormal patterns of resource consumption.
8. Watermarking Utilize watermarking techniques to detect and track unauthorized use of LLM-generated outputs.
9. Graceful Degradation Design the system to function partially under heavy load, ensuring continued operation even when full functionality cannot be maintained.
10. Limit Queued Actions and Scale Robustly Place limits on queued actions and total actions, while employing dynamic scaling and load balancing to maintain consistent performance.
11. Adversarial Robustness Training Train models to identify and mitigate adversarial inputs and attempts to extract sensitive information.
12. Glitch Token Filtering Create lists of known glitch tokens and scan the output to avoid adding them to the model's context window.
13. Access Controls Enforce strong access controls, such as role-based access control (RBAC), and adhere to the principle of least privilege to restrict unauthorized access to LLM repositories and training environments.
14. Centralized ML Model Inventory Maintain a centralized inventory or registry of production models, ensuring proper governance and secure access control.
15. Automated MLOps Deployment Implement automated MLOps pipelines with governance, tracking, and approval processes to strengthen deployment controls and access management in the infrastructure.
Final Words:
The OWASP Top 10 for LLMs highlights evolving AI security risks. Stay informed and proactive to maximize AI benefits while protecting your systems. Review your current AI security protocols. Are they aligned with the latest OWASP Top 10 for LLMs standards?