TL;DR
Cloud-native applications have changed how businesses build and scale software. Misconfigurations have quietly become one of the biggest security risks.
What Is Application Security Posture Management
ASPM is a unified and continuous approach to securing applications from the moment code is written to the moment it runs in production. Instead of treating scanners and cloud checks as separate sources, ASPM builds a single risk model by ingesting data from every stage of the SDLC.
Most ASPM platforms pull signals from:
- SAST (code-level flaws)
- SCA / SBOM (package vulnerabilities and software composition)
- DAST / API testing
- IaC scanners (Terraform, CloudFormation, ARM/Bicep, Helm, Kustomize)
- Container registries (ECR, ACR, GCR, Harbor)
- Kubernetes APIs (workloads, policies, admission events)
- Cloud provider APIs (IAM, network rules, storage configs, database exposure)
- Secrets scanners (high-entropy string detection, token formats)
Instead of storing these as flat lists, ASPM models them as a graph, linking:
repo → commit → build → artifact → image → pod → service → ingress → data store
Every vulnerability, misconfiguration, or runtime signal is attached to a node in this graph. This gives security teams the missing context that determines:
- Whether a vulnerable library is reachable
- Whether a misconfiguration exposes a sensitive route
- Whether a container setting allows privilege escalation
- Whether a secret leak gives access to a live service
- Whether an exploit path crosses multiple microservices
This is the difference between having 5,000 alerts and understanding which 40 can actually be used against you.
ASPM vs. Traditional AppSec
| ASPM |
Traditional AppSec |
| Continuous monitoring across the full SDLC |
Point-in-time scans before release |
| Unified code-to-cloud visibility |
Siloed tools that don’t correlate findings |
| Risk-based triage using reachability and exposure |
Severity-only triage (CVSS-driven) |
| Automated workflows integrated into pipelines |
Manual coordination between teams |
| Live runtime awareness (K8s, APIs, cloud resources) |
Static scanning with no runtime context |
| Continuous compliance tied to real configs |
Reports that age the moment they’re created |
What Actually Breaks in Cloud Native Apps
Cloud-native applications move quickly, and that speed often creates small gaps that expand into real exposure. These issues don’t show up in one place. They appear across storage layers, service routing, Kubernetes workloads, container builds, secrets handling, and application logic. Most teams only notice them once they’ve already combined into a workable attack path.
Below is how these weak spots form and what they look like in technical terms.
Storage and Data Exposure
Storage misuse is one of the most common causes of cloud incidents because defaults vary across providers, and teams often change settings during development.
Typical failure patterns include:
- S3 buckets with Block Public Access disabled, combined with overly broad bucket policies such as Principal: "*".
- Azure Blob containers allowing anonymous access through SAS URLs with long-lived or missing expiry times.
- GCS buckets using legacy ACLs, not IAM bindings, causing accidental public exposure.
- Databases deployed without encryption or TLS enforcement, especially in dev environments mirrored to production.
One real-world pattern: a debug export stored in an S3 bucket with ACL: public-read, no SSE-KMS, and no lifecycle policy. It sits unnoticed until a scanner or attacker indexes it.
Service and Network Exposure
Cloud-native networks are built from many independent components—load balancers, API gateways, service meshes, virtual networks, security groups—and a single rule can change the entire exposure surface.
Common technical issues:
- Security Groups with 0.0.0.0/0 allowed for SSH, RDP, or internal admin ports.
- Kubernetes Ingress rules routing external traffic directly to internal services.
- API Gateway endpoints deployed without authorization or throttling.
- NACLs or VPC routes that unintentionally expose internal subnets.
One example: an NGINX ingress pointing to an internal admin pod, combined with a public load balancer created automatically by a Helm chart.
Kubernetes Weaknesses
Kubernetes is powerful, but it amplifies missteps if policies and workload settings aren’t strictly enforced.
Where things break:
- Pods running as root (runAsUser: 0) with allowPrivilegeEscalation: true.
- Admission controllers left in audit mode, meaning unsafe workloads are logged but still allowed.
- Workloads using hostPath mounts, exposing node file systems.
- Outdated or misconfigured CNI plugins, allowing unintended cross-namespace traffic.
- RBAC bindings granting cluster-admin permissions to service accounts used by CI pipelines.
These gaps turn minor application bugs into node-level risk.
Container-Level Risks
Containers inherit risks from Dockerfiles, base images, and runtime settings. When these drift, they create reliable pivot points for attackers.
Technical patterns:
- Containers running with CAP_SYS_ADMIN or CAP_NET_ADMIN, giving near-root access.
- Writable root file systems, allowing an attacker to add binaries or modify configuration.
- Outdated base images lacking patched system libraries.
- Misconfigured seccomp or AppArmor profiles, leaving risky syscalls exposed.
For example: a container built from node:14 months after end-of-life, combined with writable root FS and elevated capabilities.
Secrets and Credential Mistakes
Secrets propagate quickly across cloud-native systems because everything integrates through APIs, CI/CD, and environment variables.
Frequent issues:
- AWS Access Keys committed in Git, identifiable by patterns like AKIA[0-9A-Z]{16}.
- JWTs with long expiration stored in environment variables.
- Kubernetes Secrets stored unencrypted (base64 is not encryption).
- CI/CD tokens reused across pipelines, giving more access than needed.
These mistakes often become the first step in a lateral-movement chain.
Application-Level Exploit Paths
Even with strong infrastructure security, application logic often opens a direct route for attackers.
Common failures:
- Reachable RCE vulnerabilities confirmed through call-graph or static analysis.
- SSRF routes such as /fetch?url=http://169.254.169.254/latest/meta-data/.
- GraphQL servers with no depth limits (max_depth) or cost rules.
- Weak session and token management, including missing signature checks.
- Inconsistent authorization checks across microservices, allowing privilege jumps.
These aren’t isolated issues. They combine with misconfigurations to form complete attack paths.
The Real Reason These Issues Grow
Each team works with a different view of the system. Developers focus on code, platform engineers concentrate on clusters, cloud teams manage resources, and AppSec reviews scanner outputs. Individually, these views make sense, but together they leave gaps. That’s how a relaxed ingress rule, a reachable RCE, and an exposed database end up forming a complete attack path without anyone realizing it.
ASPM solves this by bringing all of those signals into one clear view, so nothing slips through the cracks.
How ASPM Stops Misconfigurations Before They Become Real Exposure
Once you understand why ASPM becomes the single source of truth for application risk, the next question is practical: How does it actually prevent misconfigurations and vulnerable components from turning into full-blown issues?
The strength of ASPM lies in the way it embeds itself across the entire software lifecycle, catching problems at the point where they are easiest to fix and most visible to the teams responsible for them.
ASPM does not work by adding another scanner or another dashboard. It works by placing guardrails at each stage of delivery, from code to runtime, so problems surface early and never get the chance to stack together. This creates a continuous layer of protection that keeps configuration drift, privilege mistakes, container risks, and exposure paths from slipping into production.
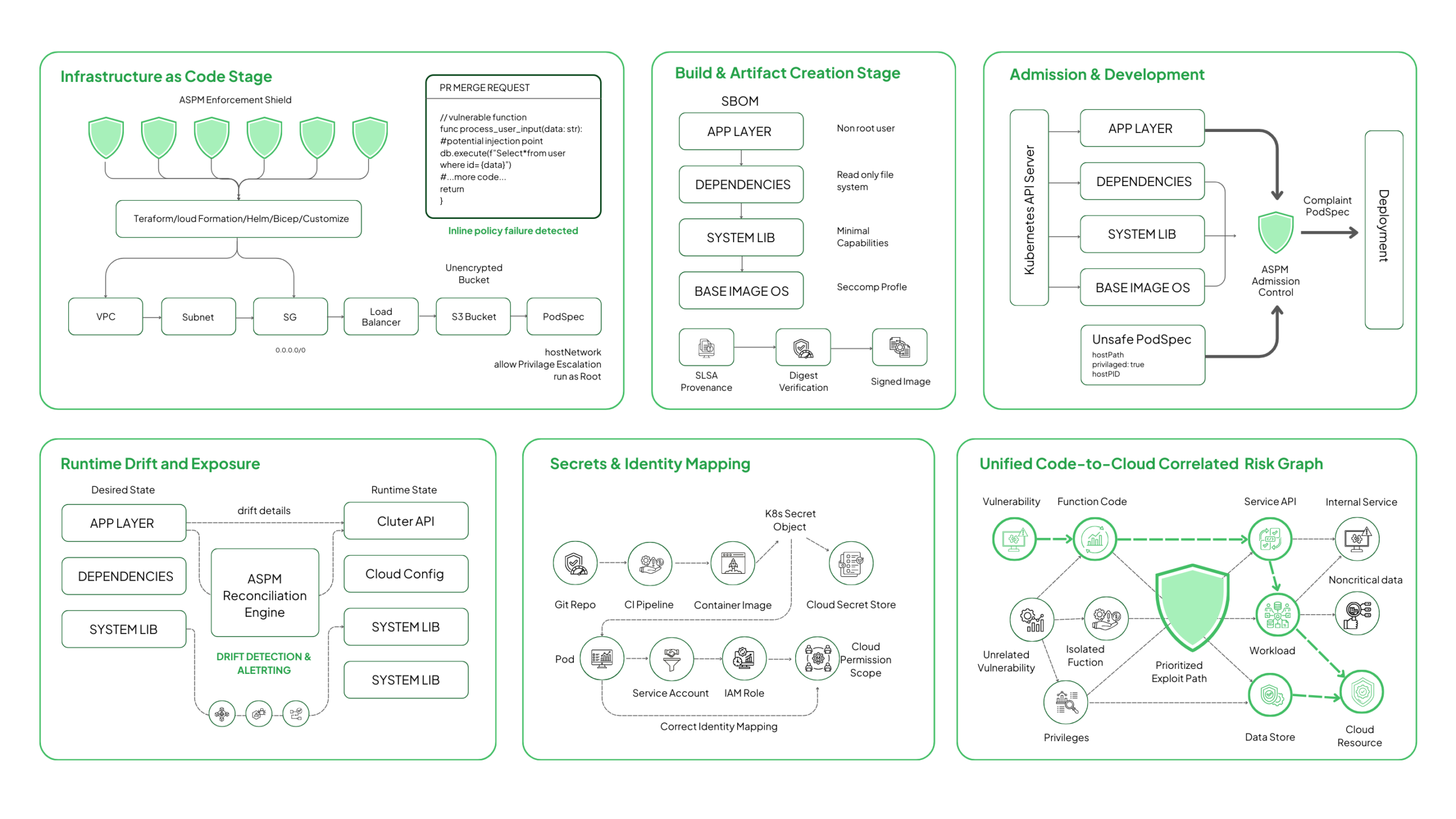
 Catching Issues in IaC Before They Deploy
Catching Issues in IaC Before They Deploy
Infrastructure as Code is the first point where real misconfigurations emerge. ASPM evaluates IaC definitions like Terraform, CloudFormation, ARM/Bicep, Helm, and Kustomize against security baselines before those resources materialize in the cloud or Kubernetes.
Teams receive feedback directly inside PRs or CI pipelines, not after deployment.
ASPM makes this easier to manage by:
- Flagging unsafe IaC patterns during code review
- Suggesting corrected configurations aligned with organizational baselines
- Preventing high-risk templates from being merged or deployed
- Creating automated pull requests with fixed values
For example, ASPM can block Terraform resources with unrestricted CIDRs (0.0.0.0/0), require cloud storage encryption via AWS SSE-KMS or GCP CMEK, validate Kubernetes PodSecurityContext fields, and deny creation of public-facing load balancers tagged as internal.
This stops misconfigurations before they appear in any cloud account or cluster.
Strengthening the Build Stage With Container and Image Checks
The build stage merges application code, dependencies, system libraries, and container runtime settings. ASPM evaluates the entire artifact rather than only package-level vulnerabilities.
ASPM ingests or generates SBOMs (CycloneDX/SPDX), validates image digests, checks SLSA provenance attestations, and inspects Dockerfile directives to ensure non-root execution, read-only root filesystems, and minimal Linux capabilities.
It also ensures consistency across base images and prevents drift between approved and used images.
ASPM checks for:
- Containers running with unnecessary privileges
- Writable root filesystems
- Outdated or vulnerable base images
- Packages that introduce reachable vulnerabilities
ASPM can identify CAP_SYS_ADMIN, CAP_NET_ADMIN, or unsafe seccomp profiles, verify that all images are pulled by digest instead of tags, and catch images missing mandatory AppArmor or seccomp policies.
Catching these issues now prevents operational debugging later once the service is deployed.
Stopping Unsafe Workloads at the Cluster Edge
Kubernetes admission is the final checkpoint before workloads become active. ASPM integrates with admission controllers to validate workloads at deployment time and block configurations that introduce lateral movement or privilege escalation.
ASPM supports this stage by:
- Enforcing workload policies aligned with security baselines
- Blocking deployments with unsafe capabilities
- Ensuring images meet validation requirements
- Detecting misalignment between declared and actual configuration
ASPM evaluates PodSecurityAdmission levels, denies hostPath mounts, checks for hostPID/hostIPC usage, verifies seccomp profiles, enforces namespace-scoped guardrails, and ensures image signatures (Cosign/Notary) match trusted registries.
Platform teams gain confidence that the cluster will not accept workloads capable of breaking isolation boundaries.
Watching for Drift Once Workloads Are Live
Even strict pipelines cannot prevent drift. Live clusters change through scaling, operator actions, autoschedulers, or emergency patches. ASPM continuously reconciles the desired state with the runtime state.
Drift detection matters because:
- It shows when live resources no longer match secure baselines
- It helps surface misalignment before they become exploitable
- It reveals operational changes that bypassed review
ASPM compares IaC state with AWS Config/Azure ARM/GCP Asset Inventory, monitors Kubernetes API server for runtime spec changes, detects capability elevation inside pods, flags new ingress routes created by service mesh rewrites, and identifies newly public cloud load balancers or changed VPC routing paths.
This ensures misconfigurations do not quietly accumulate into new attack paths.
Identifying the Risks Created by Secrets and Credentials
Secrets often move faster than teams expect. ASPM tracks secret exposure across repositories, pipelines, workloads, and cloud secret stores.
Common issues include:
- Secrets committed in repos
- Environment variables storing sensitive values
- Unrotated tokens used across multiple services
- Service accounts with broader access than required
ASPM uses entropy analysis, token-format detection (AWS keys, JWTs, OAuth tokens), Kubernetes Secret inventory scanning, and IAM/SID relationship mapping to locate exposed or over-privileged credentials. It also evaluates whether leaked credentials map to privileged roles when pods assume cloud identities (IRSA, Workload Identity, STS).
This removes an entire category of predictable, high-impact entry points.
Why This Approach Works
ASPM’s value is not in scanning more things. It is in aligning every stage of the delivery cycle with a consistent standard, revealing issues at the moment they appear, and linking them to the right owners with full technical context. This prevents misconfigurations from piling up, prevents workload risks from becoming live attack surfaces, and prevents secrets from turning into entry points.
All of this happens in a way that supports the speed and autonomy of cloud native teams, not restricts them. That is what makes ASPM sustainable, and why it becomes a core control rather than an extra layer of overhead.
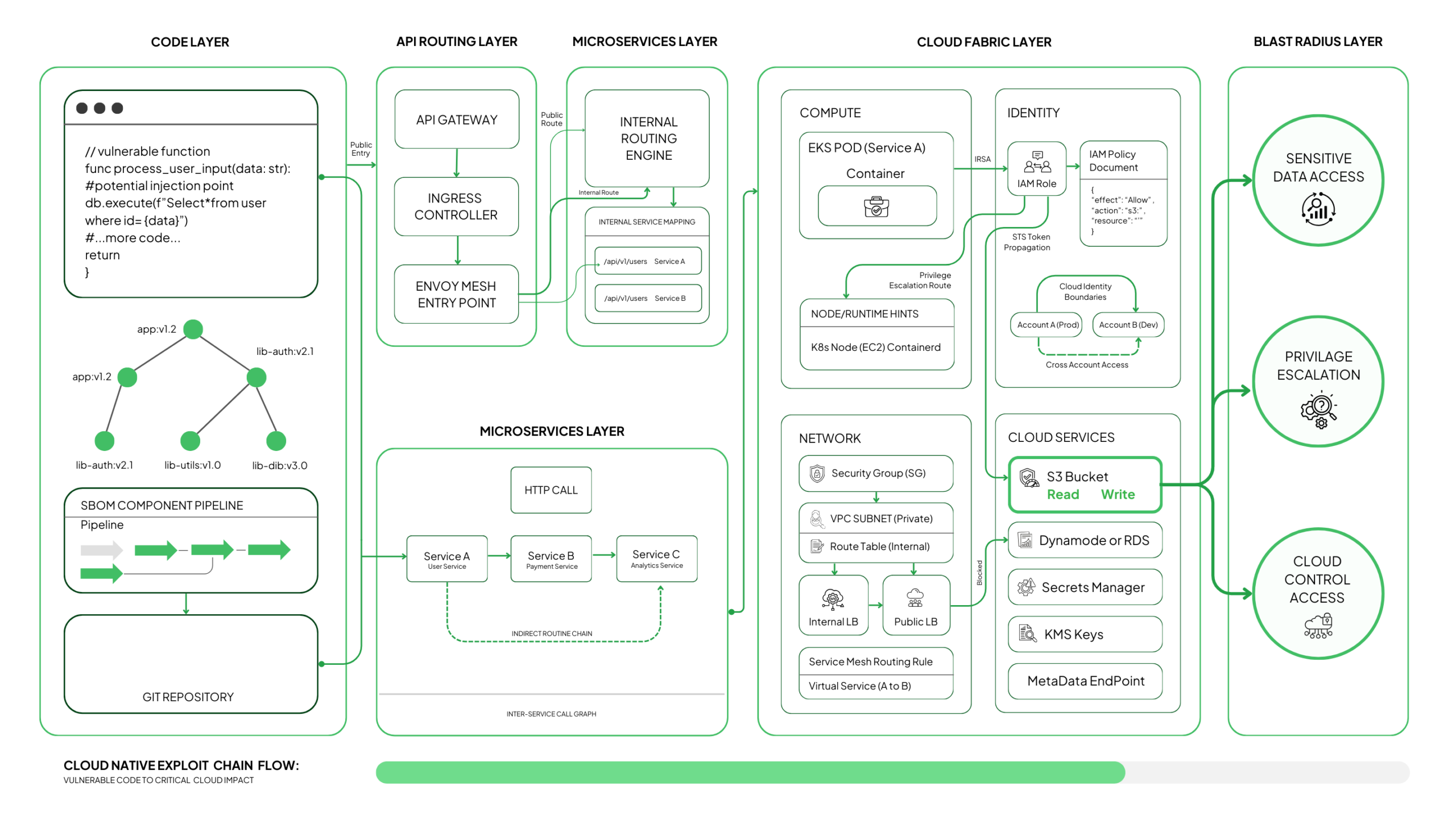
How ASPM Stops Exploitable Vulnerabilities From Turning Into Real Attacks
Misconfigurations create openings, but vulnerabilities are what attackers use to establish control. In cloud native environments, a single exploitable flaw can move through containers, services, and cloud resources faster than most teams can trace. What makes ASPM effective is its ability to analyze vulnerabilities the way an attacker would: by checking reachability, exposure, execution paths, and supporting conditions inside the environment.
ASPM does not look at a vulnerability in isolation. It evaluates the conditions needed for exploitation and whether those conditions exist in the live application stack. This is what turns traditional vulnerability scanning into true exposure analysis.
 Understanding Reachability Through Real Execution Paths
Understanding Reachability Through Real Execution Paths
The only vulnerabilities that matter are the ones that can be executed. That depends on how code paths, user input, and network entry points line up inside your system.
Reachability becomes clear when you look at:
- how the call graph flows from entry points to vulnerable functions
- how user-controlled parameters move through handlers into deeper logic
- how API Gateway, Ingress, or Envoy routes connect external traffic to internal services
- how microservices exchange requests that eventually reach the vulnerable method
- how runtime activity confirms that the function is actually invoked under load
A critical CVE hidden behind dead code is noise. A medium-severity flaw that sits directly behind an untrusted route becomes an immediate risk. The difference comes from understanding the execution path, not from reading a severity label.
Seeing Exploit Chains Across Microservices
Cloud-native architectures distribute logic across many discrete services, and exploitable paths often emerge only when those services are chained in a certain order.
Once you analyze the call flow and routing topology, patterns appear:
- internal services are unintentionally reachable because a public service proxies input without enforcing identity
- resolver chains in gRPC or GraphQL that reach logic not meant for public consumption
- downstream calls that feed untrusted data into components that expect sanitized input
- edge services exposing routes that give attackers a way into deeper layers
Vulnerabilities that look isolated on a scanner become meaningful once their downstream dependencies are visible.
Understanding Exposure Through Live Routing and Deployment State
Whether a vulnerability matters depends heavily on how the component is deployed. Real risk emerges when deployment characteristics align with logical reach.
Key exposure conditions include:
- public ingress or load balancers forwarding external traffic directly to the affected service
- API Gateway routes that bypass authentication or allow broad methods
- namespace placement that puts the service in a zone intended for public traffic
- service mesh rules that permit or restrict lateral movement to this component
- access from the component to sensitive databases, cloud storage, or secrets stores
A service running a vulnerable function that cannot be reached stays contained. A service with the same flaw exposed through a public path with access to internal data becomes a primary attack target.
Some of the most damaging breaches begin with a simple SSRF chain. The technical patterns behind SSRF show up in how requests are built, where parameters travel, and what the container network allows the service to contact.
Once you analyze request structures and internal routing, several indicators emerge:
- endpoints that accept arbitrary URLs or redirect targets
- functions that forward requests to internal hosts without filtering
- container networking that permits access to metadata endpoints or control-plane IPs
- lack of IMDSv2 enforcement or metadata hop limits
- absence of network policies isolating workloads from cloud control-plane services
These small details determine whether an attacker can jump from an HTTP parameter into cloud-level credentials.
Uncovering Identity and Session Weaknesses in Application Logic
Session and token handling often expose more attack paths than infrastructure misconfigurations. Once you look at how identity flows across microservices, it becomes clear where escalation opportunities arise.
Weak points often come from:
- inconsistent validation of JWT signatures or token issuers
- sessions that persist across services without synchronized invalidation
- privilege checks implemented in one service but assumed in another
- identity propagation that exposes internal roles through external session data
- long-lived tokens embedded in service-to-service communication
These flaws give attackers the ability to escalate privileges or move laterally, even if the infrastructure posture is strong.
Mapping API and GraphQL Attack Surfaces
APIs and GraphQL layers expand the attack surface through flexibility. Understanding where risks concentrate requires following resolver logic, query depth, mutation behavior, and how request parameters propagate.
Deep inspection reveals issues such as:
- resolvers that pull sensitive fields without verifying caller permissions
- unlimited query depth or cost, allowing enumeration and data draining
- mutations that bypass RBAC checks
- parameters passed to internal functions without input filtering
- schema elements unintentionally left exposed in introspection results
This level of detail makes it clear which API surfaces can be abused and which stay contained.
Determining Whether Container Vulnerabilities Can Escalate
Container vulnerabilities become meaningful only when paired with specific runtime conditions. Understanding those conditions requires looking at how the workload actually runs.
Runtime context exposes whether:
- the pod runs with elevated capabilities like CAP_SYS_ADMIN or CAP_NET_ADMIN
- the root filesystem is writable, allowing tampering
- the seccomp or AppArmor profile is permissive enough to allow privileged syscalls
- hostPath mounts expose node-level directories to the container
- the node OS or kernel version contains exploitable weaknesses reachable from the container
The same vulnerability has radically different risk levels depending on these settings.
Correlating Everything Into a Realistic Exploit Narrative
The final step is correlating these layers into a coherent understanding of what can be exploited and how. Once you connect all the layers, the sequence becomes clear.
- A vulnerability in code ties to the specific function that exposes it.
- That function is reachable through a particular service.
- The service runs inside a workload with defined privileges and capabilities.
- That workload has access to specific data stores or cloud resources.
- And all of it sits on top of the network and identity paths that determine whether an attacker can move from one point to the next.
When you see these relationships as a single chain instead of isolated findings, the actual exploitability becomes obvious, and the priority does too.
The ASPM Metrics Every CISO Should Track
Once ASPM is in place, the next step is understanding what its data actually tells you. CISOs don’t need long lists of findings. They need signals that show whether the program is working, where risk is forming, and how teams are responding. ASPM turns the complexity of cloud native environments into a set of metrics that help you steer the entire application security effort with confidence.
1. Exploitable Paths Resolved Over Time
Instead of tracking vulnerabilities in bulk, ASPM highlights the issues that can be exploited inside your environment. Monitoring how these paths appear and disappear gives you a realistic view of whether your program is improving.
Useful signals include:
- Exploitable paths open at the start of a period
- New exploitable paths detected
- Exploitable paths resolved
- The average time each remained open
This shows whether meaningful risk is shrinking, not just whether tickets are being closed.
A traditional MTTR metric blends everything. ASPM refines this by measuring remediation time only for issues that influence the likelihood or impact of an attack.
MTTR calculation reflects whether:
- The vulnerability is reachable
- The service is externally or internally exposed
- Sensitive data is involved
- Mconfigurations amplify the risk
This gives you a realistic measure of how well your teams are containing serious threats.
3. Application-Level Risk Patterns
Cloud native risk never spreads evenly across applications. Some teams create more exposure than others, and some services evolve faster than the rest. ASPM brings these patterns to the surface so you know where to intervene.
Patterns you can quickly spot:
- Applications generating repeated high-risk findings
- Teams that consistently meet or miss SLAs
- Services showing clear posture improvements
- Areas where engineering support or guardrails are needed
These insights help you direct resources and attention to the right places.
4. SLAs Aligned With Actual Exposure
ASPM helps you define SLAs based on the conditions that make an issue dangerous, not on static severity tags.
SLA logic reflects:
- Exposure level of the affected service
- Sensitivity of the connected data
- whether active exploits exist
- The impact of a potential compromise
This gives teams timelines that match the true urgency of each issue.
5. Posture Trends for Leadership and Audit
Leadership conversations focus on progress, not raw numbers. ASPM gives you reporting that clearly shows how your program is moving.
Key posture indicators include:
- Quarter-over-quarter exposure reduction
- Distribution of high-risk issues
- improvements in drift, configuration quality, and policy adherence
- Evidence that issues are being caught earlier in the lifecycle
These metrics make it easier to communicate impact and demonstrate control.
Your Next Step Toward a Stronger ASPM Program
Building a solid ASPM practice begins by understanding how code, configurations, and runtime behavior influence real risk. Once that visibility is in place, it becomes easier to guide teams, act on the right signals, and keep security aligned with the evolution of your applications.
If you want to see a practical, unified way to bring this approach to life, Strobes gives you a clear example of ASPM built for modern engineering workflows. It puts the right context in front of the right teams without slowing delivery.
Discover how Strobes ASPM gives you a cleaner, faster path to application security.